目录
O、长连接与短链接
dubbo用长连接。
一、JDK的HttpClient
1.1、是否缓存复用是动态处理的:
1.2、HttpURLConnection、HttpClient、KeepAliveCache三个类的简单关系为:
1.3、链接缓存:继承自HashMap的实现。map的key也是特殊定义的
1.4、缓存类实现(原理同Redis的)
缓存失效机制:A、启动之后自己主动清理自己。B、同时去get的时候如果过期也失效清理。
1.5、所以JDK的HTTPClient在实际应用中基本是不能长连接复用的!!!
1.6、Feign默认使用JDK的HTTP,需要优化
二、Apache的HttpClient
ApacheHttpClient实现类:
Post请求调用setEntity设置请求参数时,简单的可用字符串,如果传过来是字符数组byte[]也可以直接用。
HttpEntity接口有多种实现类:
三、OkHttpClient
所以,直接跟web前端打交道的网关层选择ApacheHttpClient,各个后端服务之间的调用选择OkHttpClient。
四、怎么验证连接走的是长连接还是短连接?
O、长连接与短链接
当网络通信时采用TCP协议时,在真正的读写操作之前,server与client之间必须建立一个连接,当读写操作完成后,双方不再需要这个连接时它们可以释放这个连接,连接的建立是需要三次握手的,而释放则需要4次挥手,所以说每个连接的建立都是需要资源消耗和时间消耗的。
长连接:所谓长连接,指在一个TCP连接上可以连续发送多个数据包,在TCP连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接,一般需要自己做在线维持。维持长连接耗资源,所以用户量多了很可能把服务器资源耗尽,所以需设置保持长连接的时间。
短连接:短连接是指通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接。
一台计算机最多只能开启 65535 个端口,单个客户端理论上最多只能与服务端同时建立 65535 个 socket 连接。
应用场景:
长连接多用于操作频繁(读写),点对点的通讯,而且连接数不能太多情况。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,次处理时直接发送数据包就OK了,不用建立TCP连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
dubbo用长连接。
Dubbo 缺省协议采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及 服务消费者机器数远大于服务提供者机器数的情况。 反之,Dubbo 缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很 低。

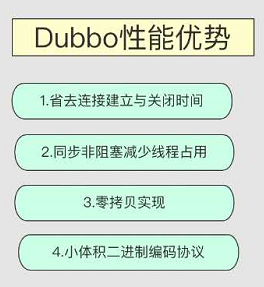
因为是单一长连接,所以传输大数据量的话会长时间占用连接!!!需要新建一个专用私有连接。



而像WEB网站的http服务一般都用短链接(在HTTP/1.0中只支持短连接。,http1.1默认长连接, keep alive 带时间,操作次数限制的长连接),因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连接好。但实际一般的web网站会加载各种js、css等静态资源,用短连接会导致加载很慢!所以还是得用长连接,用保持连接时间比较短的长连接。
但,单从HTTP协议角度是没有长短链接一说的,长短链接其实说的是TCP协议层的。HTTP协议说到底是应用层的协议,而TCP才是真正的传输层协议,只有负责传输的这一层才需要建立连接。TCP连接是一个双向的通道,它是可以保持一段时间不关闭的,因此TCP连接才有真正的长连接和短连接这一说。说HTTP请求和HTTP响应会更准确一些,而HTTP请求和HTTP响应,都是通过TCP连接这个通道来回传输的。

在长连接中一般是没有条件能够判断读写什么时候结束,所以必须要加长度报文头。读函数先是读取报文头的长度,再根据这个长度去读相应长度的报文。
设置长连接:浏览器或者服务器在其头信息加入这行代码 Connection:keep-alive
一、JDK的HttpClient
服务之间链接,最基本的就是jdk的HttpURLConnection:(Feign默认使用的也是HttpURLConnection 基础连接类)。

该HttpURLConnection类的内部,使用了JDK自带的 HttpClient 请求客户端类去负责完成底层的socket流操作。另外,JDK还提供了一个简单的长连接缓存类 KeepAliveCache,实现HttpClient 请求客户端类的缓存和复用。


1.1、是否缓存复用是动态处理的:
静态属性 keepAliveProp 的值,是决定HttpClient 的实例对象是否放入长连接缓冲池 KeepAliveCache 的一个重要关键属性值。也就是说,这个属性为true,则 HttpClient 实例对象具备复用的可能,否则,HttpClient 实例对象不能被复用。

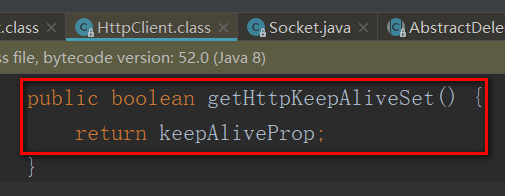






1.2、HttpURLConnection、HttpClient、KeepAliveCache三个类的简单关系为:
每个HTTP请求都是一个HttpURLConnection实例,每个请求都会有一个 HttpClient 客户端实例,一个HttpClient 实例都持有一个TCP socket 长连接。如果 HttpClient 实例可以复用,则暂存在KeepAliveCache 缓存实例中。HttpURLConnection 会优先从缓存中取得合适的HttpClient 客户端,如果缓存中没有,HttpURLConnection 才会选择去创建新的HttpClient 实例。
设置Keep-Alive 头“Keep-Alive:timeout=xx,max=xxx” ,其中 timeout 表示服务端的‘空闲’超时时间,max表示长连接最多处理多少个请求。则这两个值,将覆盖掉 httpClient对象的keepAliveTimeout 和 keepAliveConnections 属性的值。
通过三者之间的关系,可以看出: HttpClient 实例的复用,就是底层 TCP socket 长连接的复用。
public static HttpClient New(URL var0, Proxy var1, int var2, boolean var3, HttpURLConnection var4) throws IOException {
if (var1 == null) {
var1 = Proxy.NO_PROXY;
}
HttpClient var5 = null;
if (var3) {
var5 = kac.get(var0, (Object)null);
if (var5 != null && var4 != null && var4.streaming() && var4.getRequestMethod() == "POST" && !var5.available()) {
var5.inCache = false;
var5.closeServer();
var5 = null;
}
if (var5 != null) {
if (var5.proxy != null && var5.proxy.equals(var1) || var5.proxy == null && var1 == null) {
synchronized(var5) {
var5.cachedHttpClient = true;
assert var5.inCache;
var5.inCache = false;
if (var4 != null && var5.needsTunneling()) {
var4.setTunnelState(TunnelState.TUNNELING);
}
logFinest("KeepAlive stream retrieved from the cache, " + var5);
}
} else {
synchronized(var5) {
var5.inCache = false;
var5.closeServer();
}
var5 = null;
}
}
}
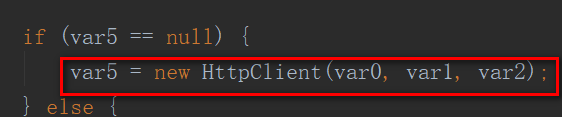
if (var5 == null) {
var5 = new HttpClient(var0, var1, var2);
} else {
SecurityManager var6 = System.getSecurityManager();
if (var6 != null) {
if (var5.proxy != Proxy.NO_PROXY && var5.proxy != null) {
var6.checkConnect(var0.getHost(), var0.getPort());
} else {
var6.checkConnect(InetAddress.getByName(var0.getHost()).getHostAddress(), var0.getPort());
}
}
var5.url = var0;
}
return var5;
}
如上代码,当取不到符合条件的缓存时:去new,调用以下方法:
protected HttpClient(URL var1, Proxy var2, int var3) throws IOException {
this.cachedHttpClient = false;
this.poster = null;
this.failedOnce = false;
this.ignoreContinue = true;
this.usingProxy = false;
this.keepingAlive = false;
this.keepAliveConnections = -1;
this.keepAliveTimeout = 0;
this.cacheRequest = null;
this.reuse = false;
this.capture = null;
this.proxy = var2 == null ? Proxy.NO_PROXY : var2;
this.host = var1.getHost();
this.url = var1;
this.port = var1.getPort();
if (this.port == -1) {
this.port = this.getDefaultPort();
}
this.setConnectTimeout(var3);
this.capture = HttpCapture.getCapture(var1);
this.openServer();//注意此处!!!
}

底层Socket:

1.3、链接缓存:继承自HashMap的实现。map的key也是特殊定义的

缓存map的key:
class KeepAliveKey {
private String protocol = null;
private String host = null;
private int port = 0;
private Object obj = null;
public KeepAliveKey(URL var1, Object var2) {
this.protocol = var1.getProtocol();
this.host = var1.getHost();
this.port = var1.getPort();
this.obj = var2;
}
public boolean equals(Object var1) {
if (!(var1 instanceof KeepAliveKey)) {
return false;
} else {
KeepAliveKey var2 = (KeepAliveKey)var1;
return this.host.equals(var2.host) && this.port == var2.port && this.protocol.equals(var2.protocol) && this.obj == var2.obj;
}
}
public int hashCode() {
String var1 = this.protocol + this.host + this.port;
return this.obj == null ? var1.hashCode() : var1.hashCode() + this.obj.hashCode();
}
}POST请求在前面就处理了不 缓存复用。key是受协议、host、端口和参数共同决定的,所以HttpURLConnection 内部的长连接复用,和URL有关:只有在URL字符串相同的情况下,才能进行复用。这就有一个问题,如果URL中带有变量值,比如 /order/1/detail、/order/2/detail ,则不同的参数,不能进行HttpClient 实例对象的复用。
1.4、缓存类实现(原理同Redis的)
缓存类同时也是个线程类,put的时候会去启动,且put的时候设置缓存失效时间。
缓存失效机制:A、启动之后自己主动清理自己。B、同时去get的时候如果过期也失效清理。
1.4.1、缓存自己去清理自己的过期缓存






1.4.2、去get缓存的时候如果过期便清理:


1.5、所以JDK的HTTPClient在实际应用中基本是不能长连接复用的!!!
和ApacheHttpClient 连接复用相比,JDK默认的HttpClient 实例对象的复用,有以下问题:
(1)JDK默认的 HttpClient 实例对象复用的粒度太小,只有URL相同的情况下,才能进行连接复用。而 ApacheHttpClient 连接复用的粒度则大很多,同路由的连接,就可以复用。
(2)在URL字符串变化比较大的场景下,JDK默认的 HttpClient 实例对象的内部连接,会保持一段时间才被释放,会占用系统的连接资源,更加不利于高并发。
所以,从以上两点出发,由于不能相同保证URL的请求数据巨大,所以不建议使用JDK默认的HttpClient 实例对象。
1.6、Feign默认使用JDK的HTTP,需要优化
1)、Feign默认使用的JDK自带的HTTP方式(基本相当于没有连接池,连接速率不够。)
2)、Feign最大的优化点是更换HTTP底层实现(使用Apache的HTTPClient或者OkHttpClient,OpenFeign实现了该支持!:OpenFeign相关配置说明 :https://blog.csdn.net/itwxming/article/details/108399511

二、Apache的HttpClient
ApacheHttpClient 连接复用的粒度则大很多,同路由的连接,就可以复用。HttpClient被用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议。
HttpClient与OkHttpClient的区别:https://blog.csdn.net/sinat_34241861/article/details/108261600
特性:
- 基于标准、纯净的java语言。实现了Http1.0和Http1.1
- 以可扩展的面向对象的结构实现了Http全部的方法(GET, POST, PUT, DELETE, HEAD, OPTIONS, and TRACE)。
- 支持HTTPS协议。
- 通过Http代理建立透明的连接。
- 利用CONNECT方法通过Http代理建立隧道的https连接。
- Basic, Digest, NTLMv1, NTLMv2, NTLM2 Session, SNPNEGO/Kerberos认证方案。
- 插件式的自定义认证方案。
- 便携可靠的套接字工厂使它更容易的使用第三方解决方案。
- 连接管理器支持多线程应用。支持设置最大连接数,同时支持设置每个主机的最大连接数,发现并关闭过期的连接。
- 自动处理Set-Cookie中的Cookie。
- 插件式的自定义Cookie策略。
- Request的输出流可以避免流中内容直接缓冲到socket服务器。
- Response的输入流可以有效的从socket服务器直接读取相应内容。
- 在http1.0和http1.1中利用KeepAlive保持持久连接。
- 直接获取服务器发送的response code和 headers。
- 设置连接超时的能力。
- 实验性的支持http1.1 response caching。
- 源代码基于Apache License 可免费获取。
ApacheHttpClient实现类:
1)、DefaultHttpClient最基本的HttpClient实现
org.apache.http.impl.client.DefaultHttpClient占用内存23字节
第一次初始化的时候需要200ms左右。以后再初始化几乎不要时间。
所以完全可以在每一个方法里面写一个new DefaultHttpClient(),作为局部变量,没必要让它作为成员变量或者静态变量。
2)、SystemDefaultHttpClient
DefaultHttpClient的子类,采用了连接池,并根据系统配置,设置成是否保持连接keepAlive
3)、AutoRetryHttpClient
顾名思义,如果服务不可用,就尝试等待几秒后,再次请求,可参考ServiceUnavailableRetryStrategy。也可自定义实现Retry类,参见老虎TTHttpRequestRetryHandler。
4)、CachingHttpClient这个有点复杂,还没看
5)、DecompressingHttpClient :有时候response的实体是压缩过的,这个类通过两个拦截器来解压。
使用步骤:
- 创建HttpClient对象
- 创建请求方法的实例,并指定请求URL。如果需要发送GET请求,创建HttpGet对象;如果需要发送POST请求,创建HttpPost对象
- 如果需要发送请求参数,可调用HttpGet、HttpPost共同的setParams(HttpParams params)方法来添加请求参数;对于HttpPost对象而言,也可调用setEntity(HttpEntity entity)方法来设置请求参数。
- 调用HttpClient对象的execute(HttpUriRequest request)方法发送请求,该方法返回一个HttpResponse
- 调用HttpResponse的getAllHeaders()、getHeaders(String name)等方法可获取服务器的响应头;调用HttpResponse的getEntity()方法可获取HttpEntity对象,该对象包装了服务器的响应内容。程序可通过该对象获取服务器的响应内容
- 释放连接。无论执行方法是否成功,都必须释放连接
Post请求调用setEntity设置请求参数时,简单的可用字符串,如果传过来是字符数组byte[]也可以直接用。
字符数组参数:byte[] data
httpPost.setEntity(new ByteArrayEntity(data));
字符串参数:String body
httpPost.setEntity(new StringEntity(body, "utf-8"));
json字符串参数:String body
StringEntity se = new StringEntity(body, "UTF-8");
se.setContentType("application/json");
se.setContentEncoding("UTF-8");
httpPost.setEntity(se);
HttpEntity接口有多种实现类:

三、OkHttpClient
https://github.com/square/okhttp
OkHttp是一款优秀的HTTP框架,它支持get请求和post请求,支持基于Http的文件上传和下载,支持加载图片,支持下载文件透明的GZIP压缩,支持响应缓存避免重复的网络请求,支持使用连接池来降低响应延迟问题。
OkHttp是一个高效的HTTP客户端
特性:
- 支持HTTP/2,允许所有同一个主机地址的请求共享同一个socket连接
- 连接池减少请求延时
- 透明的GZIP压缩减少响应数据的大小
- 缓存响应内容,避免一些完全重复的请求
使用步骤:
- 创建OkHttpClient对象
- 创建Request对象
- 将Request 对象封装为Call
- 通过Call 来执行同步或异步请求,调用execute方法同步执行,调用enqueue方法异步执行
两者性能其实各有千秋。
所以,直接跟web前端打交道的网关层选择ApacheHttpClient,各个后端服务之间的调用选择OkHttpClient。
四、怎么验证连接走的是长连接还是短连接?
在服务端服务器查看被调用的端口信息:
查看某个端口的连接情况:
linux下:查看7080端口:netstat -anp | grep 7080
Windows下:netstat -ano | findstr 7080
TCP连接的端口状态等讲解:https://blog.csdn.net/zzhongcy/article/details/38851271
短连接:客户端直接new jdk的URL的方式调用:服务端监听到的客户端调用情况,客户端的端口没有复用!!!

长连接:




